
AI Isn’t a Bubble: It’s Becoming Infrastructure (and Open Models Prove It)
Every few decades, a technology shows up that looks messy on the balance sheet but obvious in the operating model. People ask, “If it’s real, why are the leading companies losing money?”
I’ve been on the inside of this shift—building enterprise knowledge bases and internal chatbots, then spending long nights turning the messy parts (governance, cost control, accuracy, adoption) into a plain-language playbook so leadership teams don’t have to learn it the hard way.
Here’s the pragmatic take: some AI companies will absolutely fail. Some valuations will prove inflated. But LLMs as a capability are not a bubble—they’re moving in the same direction as electricity, telecom, and cloud: becoming cheaper, more standardized, and more embedded into everything.
Bubble vs platform shift: what people are mixing up
A bubble is when price and hype float away from reality—like selling condos in a city nobody actually lives in.
A platform shift is different. It’s when something becomes a new default layer—like the web browser, the smartphone, or the cloud—so even if some companies crash, the underlying capability keeps spreading.
LLMs are a platform shift because they change how work gets done: language becomes a universal interface to software, data, and workflows. It’s not “AI will do everything.” It’s “AI will sit between people and systems,” handling the drafting, summarizing, searching, translating, classifying, and “first pass” work that clogs up modern organizations.
“But AI companies are losing money.” That’s not proof the tech is fake
Losses can mean a business model is broken. They can also mean you’re watching an infrastructure build-out—like railroads, power grids, telecom networks, or early cloud.
In those eras, the early economics looked ugly for a simple reason: you have to build capacity before demand fully arrives, and you have to spend aggressively to stay competitive. That doesn’t make the capability imaginary. It means the market is in the “laying track and pouring concrete” phase.
In enterprise AI projects, I’ve seen the same dynamic in miniature: the first version looks expensive because you’re paying the setup costs—data access, security reviews, identity, logging, evaluation, and change management. The second and third deployments are cheaper because the “plumbing” is already installed.
The strongest “not a bubble” signal: the cost curve is moving the right way
A true bubble often needs rising inputs to keep the story alive. LLMs are trending the opposite direction:
- Better results per dollar: models and serving stacks keep getting more efficient.
- Smaller models doing real work: you don’t need a frontier model for every task, the same way you don’t use a supercomputer to run email.
- More deployment choices: cloud APIs, private cloud, on-prem, and local/edge options are all viable depending on the workload.
That matters because most enterprise ROI isn’t “train the world’s best model.” It’s: “Can we deliver accurate help to employees and customers—predictably, securely, and at a cost we can forecast?”
Open models change the economics: AI isn’t controlled by a single toll booth
One reason people fear a bubble is the idea that AI is a fragile ecosystem dependent on a few vendors subsidizing compute forever.
Open-weight models (like Llama and others) weaken that fear. They prove the capability is diffusing. That’s what real infrastructure does: it spreads, standardizes, and gets cheaper as more builders contribute.
Think of it like this: if only one airline could fly, airfare would be expensive and fragile. But once aircraft designs, pilots, and maintenance knowledge become widespread, flying becomes a stable industry—even though individual airlines still go bankrupt.
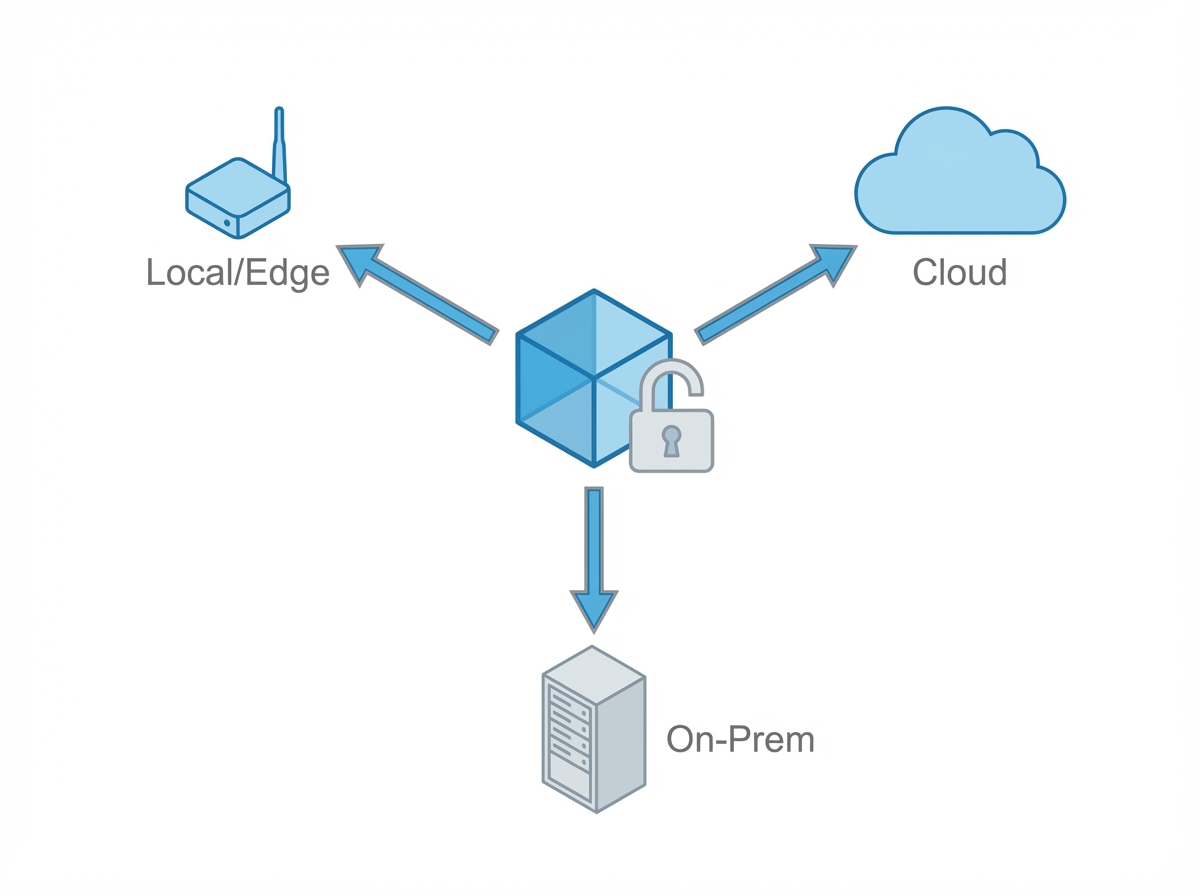
Local LLMs (yes, even on small devices) are the “AI becomes boring” moment
Let’s address the Raspberry Pi angle with precision: a tiny device won’t replace frontier models for every use case, and you’re not going to train a modern LLM from scratch on it.
But you can run smaller, efficient models locally for real tasks—summaries, classification, extraction, simple assistants, offline help, and “good enough” drafting.
That’s a big deal because it turns AI from a metered utility bill into something that feels like software again. It’s the same shift we saw when:
- computing moved from mainframes to desktops,
- storage moved from specialized arrays to commodity disks,
- servers moved from bespoke hardware to virtual machines and containers.
When a capability runs locally, it becomes harder to “pop.” It doesn’t depend on constant external funding to exist. It becomes a tool you can own.
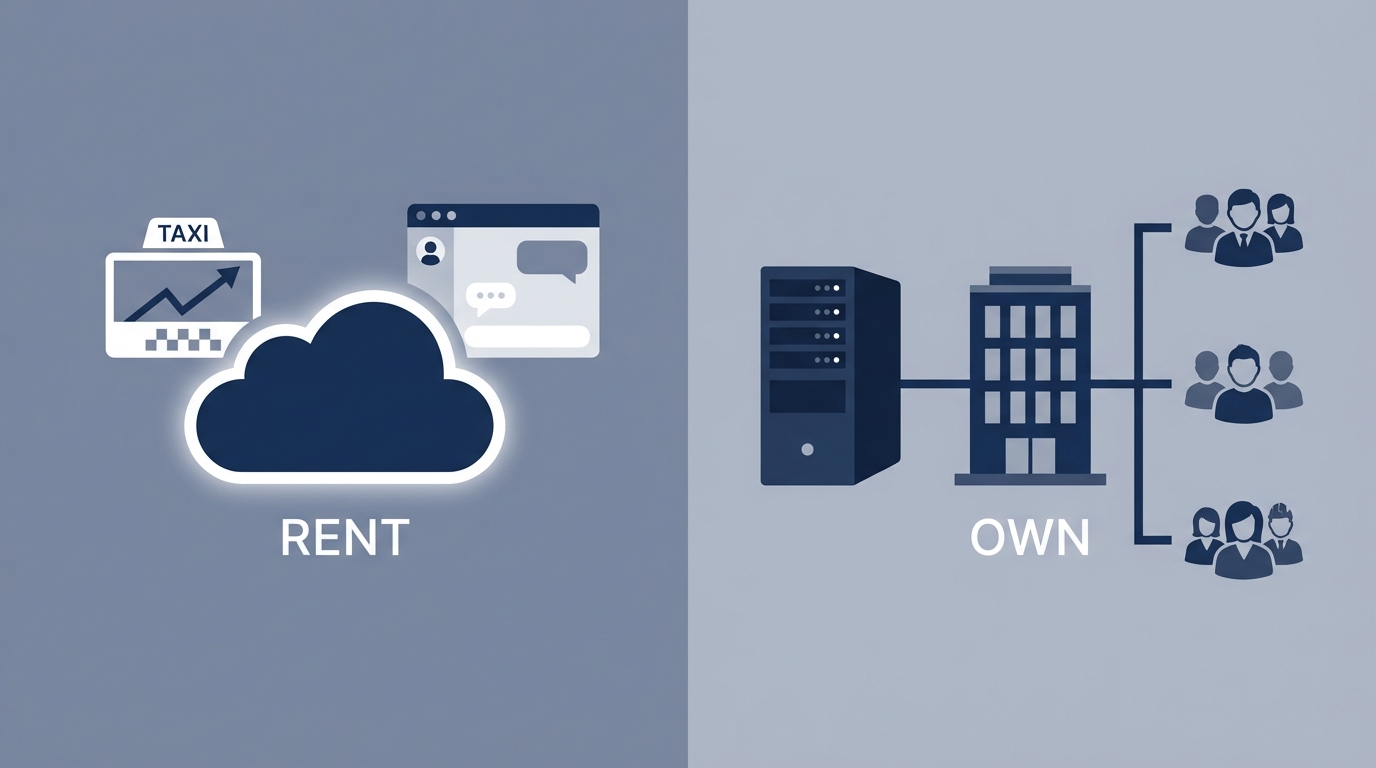
The executive decision: rent AI tools or own an AI “knowledge brain”
In enterprise settings, the most useful framing isn’t “Which model is best?” It’s:
Are we renting intelligence (a hosted chatbot that answers questions), or are we owning a knowledge brain (an internal system that reliably retrieves company truth and uses a model to explain it)?
In practice, “owning” usually means a retrieval-based approach (often called RAG): your data stays yours, and the model is the interpreter—not the source of truth. You can still use cloud models, open models, or local models, but the brain is your knowledge layer. I’ve wrote about this in another blog post, check this out Renting AI vs Owning AI Infrastructure
Five value points executives actually care about (in plain terms)
- Cost predictability: Renting feels cheap until usage spikes. Owning turns “per-question fees” into planned capacity—more like buying a fleet vs paying surge pricing for taxis.
- Governance and auditability: Owned systems can log sources, enforce access, and show “why.” That’s the difference between a documented process and hallway advice.
- IP and data control: Your internal knowledge (policies, playbooks, product details) is an asset. Owning the brain reduces accidental leakage and dependency on one provider’s rules.
- Consistency across teams: A shared brain reduces the “sales said X, support said Y” problem. One source of truth, many interfaces.
- Vendor lock-in and migration: If the knowledge layer is yours, swapping models is like swapping an engine—not rebuilding the whole car.
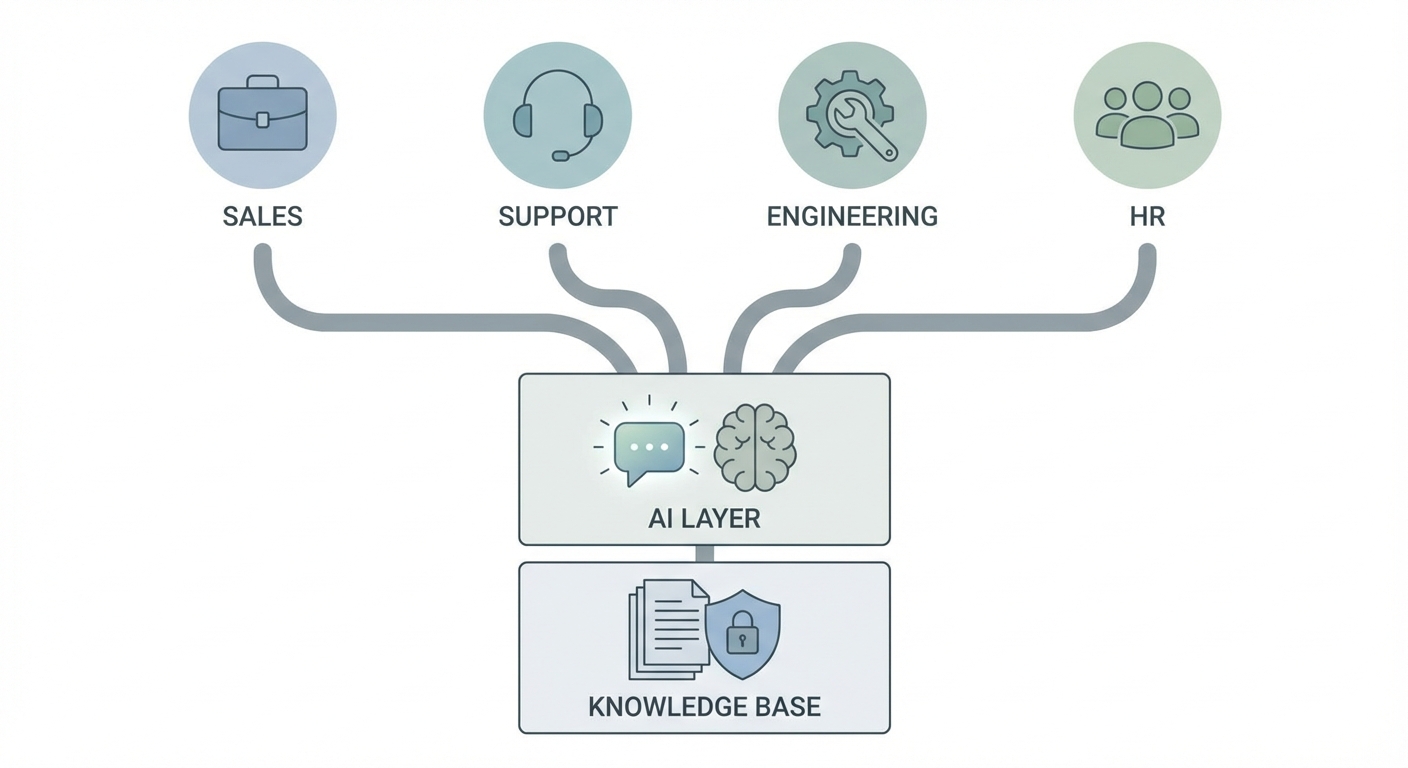
“AI is expensive to maintain.” True—and it’s exactly why it becomes infrastructure
Serving AI at scale costs money: compute, monitoring, evaluation, security, and updates. That’s real. Pretending otherwise is hype.
But here’s the counterintuitive part: those costs create pressure to optimize. And optimization is already happening—through smaller models, better serving stacks, and practical architectures where the model does the language work while systems handle facts and permissions.
In other words: maintenance cost doesn’t kill the category. It forces the category to mature—like early cloud bills forced teams to learn FinOps.
Where AI value is durable (and where it’s not)
Durable value looks like “copilot + workflow,” not “magic robot employee.” The wins I see hold up in boardroom terms:
- Faster cycle times: drafts, summaries, first-pass analysis, and code scaffolding.
- Better internal self-serve: fewer tickets because people can find answers with citations.
- Standardized execution: playbooks embedded into day-to-day work, not buried in wikis.
- Lower operational friction: less “copy/paste between systems” work—the glue work that drains teams.
Less durable value looks like “a generic chatbot that guesses.” If it can’t cite sources, respect permissions, and stay consistent, it becomes novelty—then churn.
The sober conclusion: some companies are bubbles; AI as a capability isn’t
We can hold two truths at once:
- Some AI business models will break (especially those selling undifferentiated wrappers with no data strategy).
- LLMs will still become a default layer in enterprise software, because the capability is real, compounding, and spreading—especially via open models and local deployment.
If you’re making enterprise bets, the strategic question isn’t “Is AI a bubble?” It’s “What parts do we rent, and what parts do we own?”
If it helped, share it with a CIO/CTO who’s being asked to justify the AI roadmap in one slide.







Wrap your code in
<code class="{language}"></code>tags to embed!